Qemu虚拟机e1000网卡rx_errors问题排查
问题现象
通过命令查看到网卡的rx_errors有持续的错误计数增加
|
|
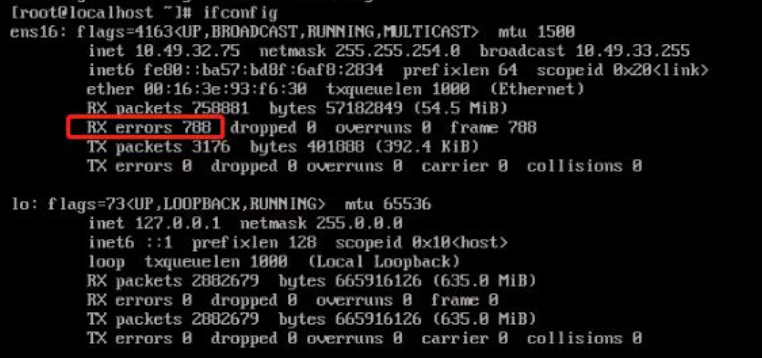
这上面什么原因导致的呢?
网卡计数说明
linux kernel关于网卡统计计数的说明参考:https://docs.kernel.org/networking/statistics.html
下面对经常遇到的错误计数counter简要介绍:
-
rx_errors
表示该网络设备上收到的坏数据包总数。该计数器包含 rx_length_errors、rx_crc_errors、rx_frame_errors的计数和其他未计数的错误。
-
rx_dropped
表示收到但未处理的数据包数,属于主机主动丢弃的数据包,例如由于缺乏资源或不支持的协议。对于硬件接口,此计数器可能包括由于 L2 地址过滤而丢弃的数据包,但不应包括由于缓冲区耗尽而被设备丢弃的数据包,这些数据包在 rx_missed_errors 中单独计数。
-
rx_length_errors
由于报文长度非法而丢弃的数据包数。关于长度的计数具体到驱动侧实现可能分为两种一种是
-
rx_long_length_errors
表示接收的报文的长度超过 MTU 的过大帧
-
rx_short_length_errors
表示报文长度小于规定的最小64字节的规范,都被计入该counter
-
-
rx_crc_errors
收到的带有 CRC 错误的数据包数量,出现这种错误基本可以任务是硬件线缆问题
-
rx_frame_errors
收到的对齐错误的数据包数量
-
rx_missed_errors
主机被动错过的数据包数量。由于缓冲区空间不足而被设备丢弃的数据包数。这通常表示主机接口比网络接口慢,或者主机没有跟上接收数据包的速度。这是网卡硬件的计数,并不在软件层。
排查思路
通常通过ifconfig、sar命令或者在/proc/net/dev看到的错误计数是一个总体或者通用的错误,可以具体通过ethtool查看对应网卡具体的错误,驱动层会细分的更详细一些
|
|
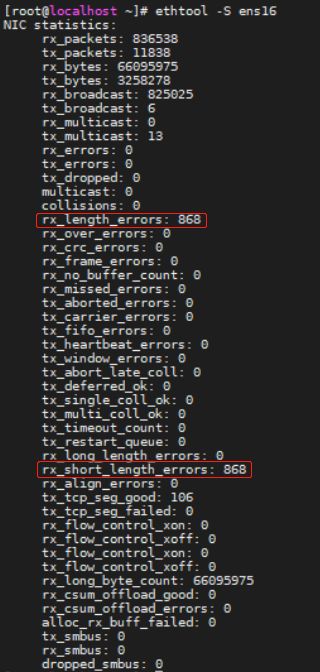
这里rx_error的错误是报文length错误引起的,确切的说是收到的报文长度太小,没有达到规定的64字节导致的,通过抓包
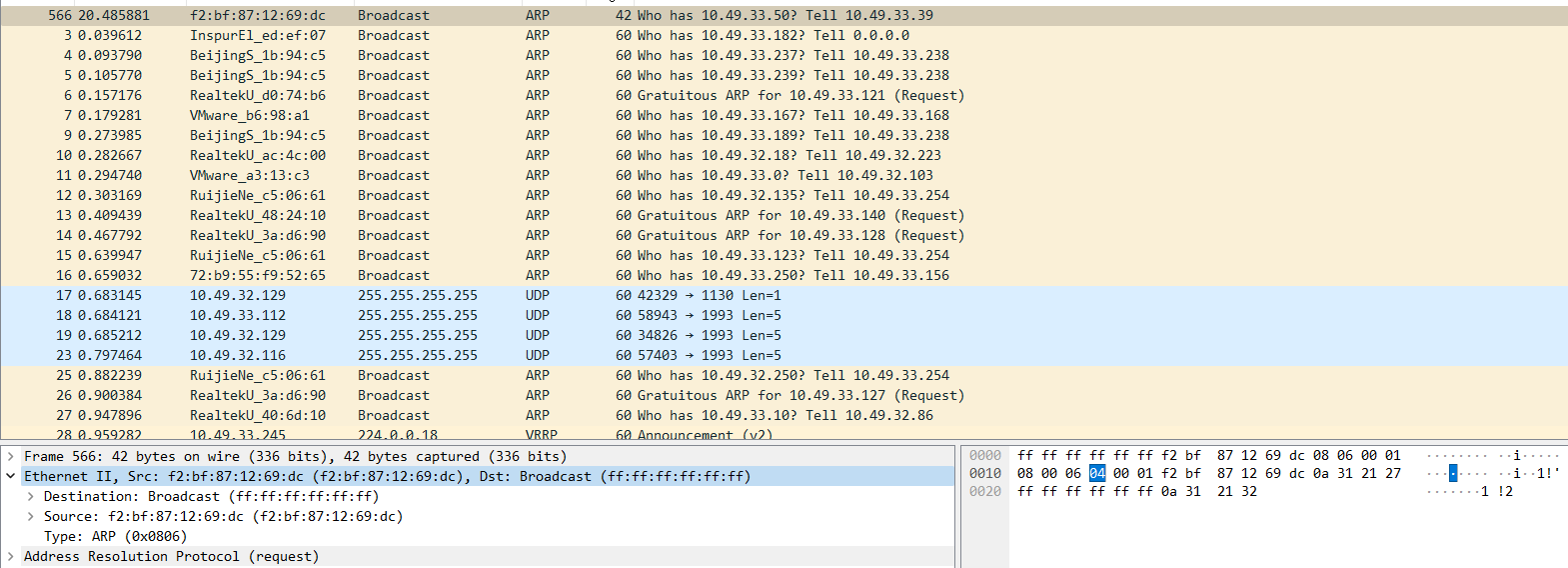
如下报文为未进行填充的ARP报文42字节
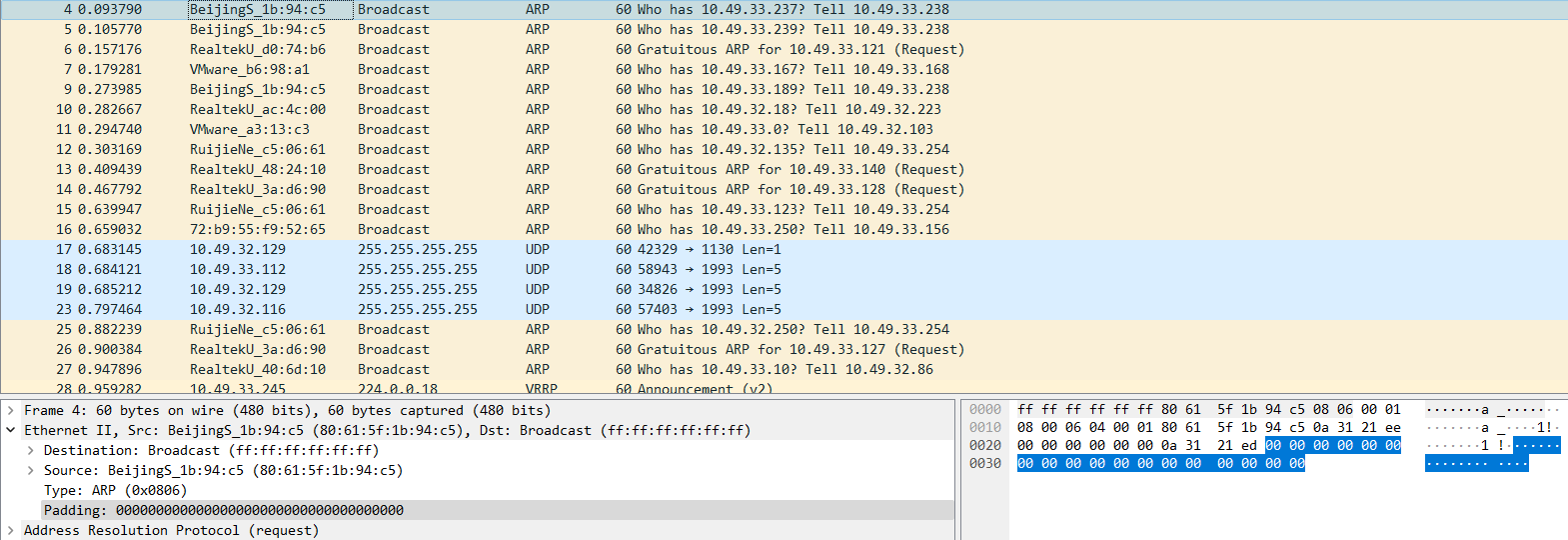
如下正常ARP报文的经过18字节填充的报文为60字节
在云计算环境下,云主机虚拟网卡使用的tap设备或者比如ovs internal端口设备,并没有以太网卡对发送最小报文64字节进行填充的要求,因为他们是虚拟设备,这类设备的物理层可能不是以太,所以它并不要求对报文的大小进行填充。这里qemu社区的解决方式在传统网卡驱动的接收方向对收到报文小于60字节(为什么不是64字节,因为CRC校验是在物理层处理的,报文到达软件时已经去掉了CRC校验4字节)填充进行一个workaround处理
具体参考:e1000-pad-short-frames-to-minimum-size-60-bytes
|
|
但是在后续另一个优化的patch又引入了一个问题,就是在对接收到的小于60字节的报文填充后,把相关计数器增加,这里实际上不应该增加,因为报文经过填充后已经是正常合法的报文,需要继续进行后续报文处理
具体参考:e1000: Implementing various counters
|
|
该引入问题在这个patch中得到修复e1000: Never increment the RX undersize count register
|
|
因为使用的是qemu版本较老,通过查看使用qemu版本代码确认,代码存在错误的将RCU增加的问题,最新版本已经解决,并且经过一下优化,不再具体在每个驱动里进行字节填充padding
具体参考:net: Pad short frames for network backends
总结
-
对应rx_errors错误可以分几个方向排查问题
-
物理层硬件问题:物理网卡、光模块、光纤线、双绞线等导致
-
软件问题,应用自己组装的数据包没有进行字节填充,或是本案例分析的qemu硬件驱动层填充的问题
-
-
rx_drops问题后续再补充😄
文章作者 计算机刨根问底
上次更新 2023-06-11
许可协议 原创文章,未经允许,禁止转载