网络设备和协议开发涉及很多字节序问题
寻址和字节顺序
对于跨越多字节的程序对象,我们必须建立两个规则:这个对象的地址是什么和我们在存储器中如何对这些字节排序。在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节序列中最小的地址。
比如,一个类型为int的变量x的地址为0x100,也就是说,地址表达式&x的值为0x100,那么,x的四个字节将被存储在存储器的0x100、0x101、0x102、0x103位置
对表示一个对象的字节序列排序,有两个通用的规则,考虑一个w位的整数,有位表示[xw-1,xw-2,…,x1,x0],其中Xw-1是最高有效位,而x0是最低有效位。假设w是8的倍数,这些位就能被分组成字节,其中最高有效字节包含位[xw-1,xw-2,…,xw-8],而最低有效字节包含位[x7,x6,…,x0]。
某些机器选择在存储器中按照从最低有效字节到最高有效字节的顺序存储对象。另一些机器则按照从最高有效字节到最低有效字节的顺序存储。前一种规则—-最低有效字节在最前面的方式被称为小端模式(little endian),大多数源自以前的Digital Equipment公司的机器,以及Intel的机器都采用这种规则。后一种规则(最高有效字节在最前面的方式)被称为大端模式(big endian)。IBM、Motorola等打断是机器采用这种规则
例如,变量x类型为int,位于地址0x100处,有个十六进制0x01234567。地址范围0x100~0x103的字节序依赖于机器类型
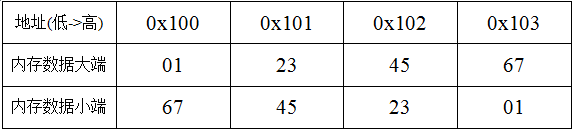
注意,在字0x01234567中,高位字节的十六进制值为0x01,而低位字节值为67。通常书写字节序列的自然方式是最低位字节在左边,而最高位字节在右边。但是这和书写数字时最高有效位在左边,最低有效位在右边的方式是相反的
网络序与主机序
网络传输一般采用大端序,也被称之为网络字节序,或网络序,即先发送高字节数据再发送低字节数据
主机序
依赖于CPU,表示字节在内存中存放的顺序。
小端 数学低存地址低 intel
大端 数学高存地址低 ppc
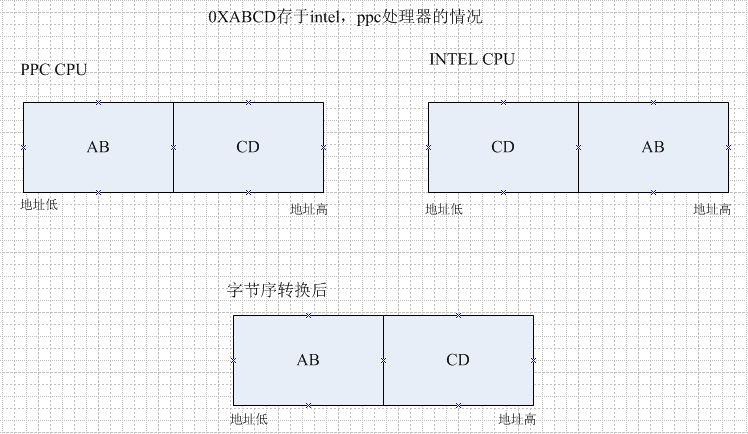
平台软件需要适应各种CPU,所以总是需要使用htonl系列宏进行字节序转换
程序举例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#include <stdio.h>
typedef union tagOrder
{
unsigned long long ul1;
unsigned int ui2;
unsigned short us3;
unsigned char uc4;
}Order;
int main()
{
Order test;
test.ul1 = 0xaabbccdd11223344;
printf("%llx\n",test.ul1);
printf("%x\n", test.ui2);
printf("%x\n", test.us3);
printf("%x\n", test.uc4);
}
|

1
2
3
4
5
6
|
## 在intel cpu运行结果
aabbccdd11223344
11223344
3344
44
|
这说明该CPU是小端模式
同样可以通过指针强转来检测CPU是大端或是小端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#include <stdio.h>
int main()
{
unsigned int uiA = 0xaabbccdd;
unsigned int *puiA = &uiA;
unsigned char *pucA = (unsigned char *)puiA;
if (0xdd == *pucA)
{
printf("The cpu is little endian\n");
}
else
{
printf("The cpu is big endian\n");
}
}
|
1
2
|
## 在intel cpu运行结果
The cpu is little endian
|
位域
在定义报文格式时,位域经常用到,位域也存在存储顺序的问题
1
2
3
4
5
|
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Ver | Flags | Message-Type | Message-Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|
例如定义这样一个Common Header的结构:
1
2
3
4
5
6
7
|
typedef struct tagCommHeader
{
unsigned char Ver:3;
unsigned char Flags:5;
unsigned char MessageType;
unsigned short MessageLen;
}CommHeader
|
内存存储情况如下

1
2
3
4
5
6
7
|
typedef struct tagCommHeader
{
unsigned char Flags:5;
unsigned char Ver:3;
unsigned char MessageType;
unsigned short MessageLen;
}CommHeader
|
内存存储情况如下
再如:
小端定义如下
1
2
3
4
5
6
7
8
|
typedef struct tagCommHeader
{
unsigned short Ver:2;
unsigned short Flags:3;
unsigned short MessageType:4;
unsigned short MessageLen:5;
unsigned short reserved:2;
}CommHeader
|
内存存储情况
bit 0~7

大端定义如下
1
2
3
4
5
6
7
8
|
typedef struct tagCommHeader
{
unsigned short reserved:2;
unsigned short MessageLen:5;
unsigned short MessageType:4;
unsigned short Flags:3;
unsigned short Ver:2;
}CommHeader
|
内存存储情况
bit 0~7

可以看到定义成相反的顺序,两者的内存存储也是不一样的,这是需要调用ntohl系列函数进行字节序转换
总而言之,位域的使用要遵循以下三个原则:
1、位域变量在不同字节序的CPU上要进行相反的定义
2、要在数据结构未填满的地方填入保留位域
3、双字和四字位域变量除以上两点外,还要做字节序转换
例如上面的情况,由于无法对结构体左字节序转换,可以定义为如下情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
typedef struct tagCommHeader
{
unsigned short Ver:2;
unsigned short Flags:3;
unsigned short MessageType:4;
unsigned short MessageLen:5;
unsigned short reserved:2;
}CommHeader;
typedef union tagHeader
{
CommHeader commheader;
unsigned short usMark;
}Header;
|